최근 리디북스에서는 판타지 연재물을 웹에서 바로 볼 수 있는 기능을 새롭게 선보였습니다.
기존에는 별도의 앱을 설치하고 다운로드하는 과정을 거쳐야 했기에 연재물을 보는 사용성이 좋지 않았습니다만, 브라우저에서 바로 볼 수 있는 “웹뷰어” 기능을 제공함으로써 사용성을 높일 수 있었습니다.
그리고 여기에 사용성을 더하기 위해 추가된 것이 이어보기 기능입니다. 짧아도 100화 이상, 길게는 1000화가 넘는 연재물에서 다음 화로의 매끄러운 연결은 매우 중요합니다. 혹은 잠시 읽기를 중단했다가 다시 돌아왔을 때, 어디까지 보고 있었는지를 빠르게 알려준다면 호흡을 이어서 작품에 더욱 몰입할 수 있을 것입니다.
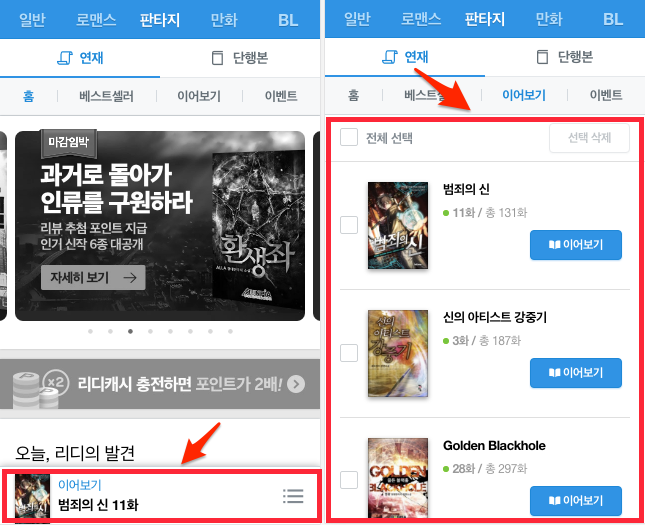
이어보기가 구현된 모습
리디북스에 로그인되어 있다면, 이곳에서 확인하실 수 있습니다.
이번 글은 이어보기 기능에 대한 개발 후기입니다. 요구 사항에 따라 여러 저장소 솔루션을 비교해 보았으며 최종적으로 Couchbase를 선택한 이유와 간단한 벤치마크 결과, 그리고 겪었던 문제를 공유합니다.
요구 사항
기획된 내용을 요약하니 아래와 같습니다.
- 연재물의 가장 마지막에 읽은 화를 알 수 있다.
- 보았던 모든 연재물에서 가장 마지막에 읽은 연재물을 알 수 있다.
- 사용자가 본 모든 연재물 목록을 확인할 수 있다.
이를 개발자 용어로 다시 풀어보면 아래와 같습니다.
- 연재물을 읽을 때마다 연재물 ID와 화(episode) 정보를 기록한다.
- 보았던 연재물을 최신순으로 정렬하여 가져온다.
- 선택된 연재물의 마지막으로 읽은 화를 가져온다.
- 목록에서 특정 연재물을 삭제한다.
이어보기는 가장 마지막에 읽은 연재물을 기억하기 위해 작품을 열 때마다 해당 정보를 기록해야 합니다. 그런데 수십 화를 연달아서 보는 연재물의 특성상 내가 어디까지 읽었는지를 조회하는 것(read)보다 내가 읽은 연재물을 기록하는 것(write)이 더 많을 것으로 판단했습니다. 즉, 읽기보다 쓰기가 더 많을 것으로 예상했습니다.
NoSQL을 쓰자
대부분의 연산이 쓰기(write)와 관련된 이상, 어떤 저장공간을 사용할 것인지가 주된 관심사였습니다.
특히 RDBMS와 NoSQL 사이에서 어떤 것을 사용할지 많은 고민과 테스트를 했고, 결국 아래와 같은 이유로 NoSQL을 사용하는 것이 적합하다고 판단했습니다.
- 현재 사용 중인 MariaDB를 그대로 사용한다면 마스터에 부담을 줄 수 있다.
- 별도로 MariaDB를 구성하더라도 운영 및 쓰기 분산하기가 여전히 어렵다.
- 반면 NoSQL은 RDBMS 대비 확장(Scale out)이 간편하므로 운영에 대한 부담이 적다.
- 단순 Key-Value 보관 용도면 충분하다.
- 이어보기 데이터는 독립적인 성격을 가지고 있어서 다른 사용자 데이터와 JOIN을 할 필요가 없다.
- 이어보기 데이터는 크리티컬한 트랜잭션이 필요하지 않다.
MongoDB vs. Couchbase
데이터를 영속적으로 유지해야 한다는 요구 사항을 충족하기 위해, Redis 등의 메모리만 사용하는 NoSQL은 제외했습니다. 물론 디스크에 기록할 수 있지만, 성능이 급감하기 때문에 실용적이지 못 합니다. 또한, 메모리 사이즈에 기반을 두기 때문에 Scale up 비용이 크고, 서비스 확장시 Scale out 빈도가 높습니다.
그래서 MongoDB와 Couchbase를 비교 대상으로 했습니다. 둘 다 도큐먼트 기반의 NoSQL이고 확장이 용이합니다. 과거에는 MongoDB가 Write lock 사용에 있어서 문제점이 있었지만, 최근 버전에서는 문제가 되지 않습니다.[1] 둘 다 기업용 서비스 및 충분한 부가 기능들을 제공하므로 선택하기 어려웠지만, 최종적으로 아래와 같은 이유로 Couchbase(CE)를 선택했습니다.
1. 이미 사내에서 다른 서비스에 사용되고 있습니다.
가장 중요한 요인이었습니다. 더 좋은 솔루션이 있더라도 어디까지나 서버 스택을 늘리는 것 이상의 효용이 있는지를 따져보아야 합니다. 이미 사용하고 있는 솔루션이 있다면, 검증이 되었을 뿐만 아니라 개발 및 운영 경험도 활용할 수 있습니다.
2. 이어보기는 복잡한 쿼리(Query)가 필요 없습니다.
이어보기에서 사용할 쿼리는 간단하기 때문에 Couchbase의 뷰(View)만으로 충분했습니다.
Couchbase, 실제 성능은 어떨까?
테스트를 하기 전 우리가 어떤 식으로 사용할 것인지 정리해야 합니다. 애플리케이션 액세스 패턴이나 동시성 문제, 데이터 구조화 등을 파악하고 그에 맞는 테스트를 진행해야 합니다. 이번 이어보기는 쓰기 연산이 보다 많기 때문에 이로 인한 뷰의 인덱싱(Indexing)에 초점을 맞추고 테스트를 진행했습니다.
성능을 위협하는 요소들
View Indexing
Couchbase는 MapReduce를 이용하여 뷰를 제공합니다. MapReduce는 일반적으로 리소스를 많이 소모하는 동작입니다. 그래서 Couchbase는 버킷의 새로 갱신된 데이터만 인덱싱하는 Incremental MapReduce라는 기법을 적용해서 리소스 소모를 줄였다고 합니다.[2] 하지만 해당 작업으로 인한 부하는 여전히 발생합니다.
Auto Compaction
Couchbase는 데이터와 인덱스를 디스크에 데이터를 저장할 때 파일에 추가하기(Append) 모드로만 쓰기를 수행합니다.[3] 그리고 오래되고 불필요한 데이터들은 추후 한꺼번에 정리하는데, 이는 디스크 쓰기 성능을 최대화하기 위함입니다.
그런데 이렇게 추가만 하게 되면 오래된 정보들은 파일의 앞에 쌓이게 됩니다. 그리고 사용하지 않게 된 데이터도 남아있습니다. 이를 주기적으로 정리해서 최적화하는 작업을 Auto Compaction이라고 합니다. 뷰의 인덱스는 디스크에 존재하기 때문에 디스크 작업이 있으면 인덱싱에 영향을 미치게 됩니다.
성능 테스트
Couchbase는 기본적으로 5,000ms마다 Index를 업데이트합니다.[2] 그리고 데이터를 비동기적으로 응답합니다. 비동기는 응답속도를 빠르게 하지만, 데이터 불일치가 발생할 수 있습니다. 데이터 불일치가 신경 쓰이고 이 시간이 길다고 생각되면, stale 옵션을 지정해서 뷰의 인덱스를 업데이트할 수 있습니다.
이어보기는 뷰가 간단하기 때문에 응답시간에 큰 문제가 없을 것으로 예상하고 stale 옵션을 꺼두었습니다. 이 옵션은 뷰를 조회했을 때 버킷의 변경사항에 따라 뷰를 인덱싱하고 데이터를 응답합니다. 하지만 예상한 것과 같이 실제로도 응답시간이 짧은지 확인할 필요가 있습니다. 그래서 다음과 같이 테스트를 진행했습니다.
테스트 환경은 아래와 같이 2-tier로 준비하고 요청을 늘려가면서 RPS를 측정했습니다.
서버 구성
- OS: Ubuntu 14.04
- Application: Couchbase Server (CE) 3.1.3
클라이언트 구성
- 클라이언트 1개에서 50개의 세션으로 요청
- 10만 사용자 가정
- 책은 1만개의 책중 랜덤으로 선택됨
- 요청의 70%는 책 읽기(Bucket Write)
- 요청의 30%는 연재물의 마지막에 읽은 책 가져오기(View Read)
그래프 분석
성능 테스트 주요 지표
- RPS : Response Per Second
- SP : Saturation Point
- Buckle zone : 시스템 과부하로 인해 내부 자원이 서로 경쟁상태나 적체 상태가 심해지기 때문에 최대 처리량보다 더 떨어지는 경우가 발생함
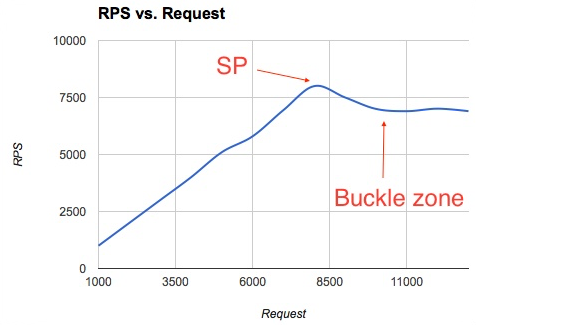
성능테스트 결과
그래프를 보면 요청이 늘어남에 따라 RPS가 선형으로 증가하지만, SP인 8,000 RPS에 도달하고 나서 Buckle zone에서 7,000 RPS로 수렴하고 있습니다. 물론 1개의 클라이언트에서 세션을 생성해서 테스트를 진행했기 때문에 서버의 성능 부족이 아닌 클라이언트의 병목 현상이 원인일 수 있습니다. 또한 JMeter나 다른 부하 테스트 툴을 사용하지 않고 간략하게 만든 테스트 툴을 사용하였기 때문에 수치가 부정확할 수 있습니다. 그러나 어디에서 병목이 있었든 현재 이 이상의 성능이 필요하지 않기 때문에 테스트 결과에 만족할 수 있었습니다.
이어보기 배포 후
모바일 브라우저 캐시 문제
이어보기 기능을 배포하자마자 당일 저녁 이슈 하나를 접수했습니다. 아이패드와 PC를 번갈아 이용할 경우 이어보기 데이터가 맞지 않다는 것이었습니다.
데이터를 쌓을 때 모든 이력을 기록하지는 않았지만, 다행히도 Couchbase에 이용기기와 시간은 기록하였기 때문에 이를 바탕으로 디버깅을 할 수 있었습니다. (서비스 초기라 할지라도 최대한 많은 이력을 남기는 것이 중요함을 다시 느꼈습니다)
원인은 아이패드의 멀티태스킹으로 인한 캐시 소멸이었습니다. 아이패드 브라우저의 캐시가 소멸되면서 마지막으로 열어두었던 페이지가 강제적으로 리로딩되었고, 이때 의도치 않게 마지막 위치 정보가 덮어씌워진 것입니다.
이 문제는 기술적으로 해결이 쉽지 않아 결국 기획을 수정하게 되었습니다. 사용자가 해당 책을 읽었다고 판단하는 기준이 “페이지를 열어본 즉시”였다면, 이를 “페이지를 열고 수 초 이상을 유지”하는 것으로 기준을 변경하였습니다. 물론 근본적인 해결책은 아니었지만, 실제 사용에는 지장이 없는 합리적인 해결책이라고 생각합니다.
Key 구조의 변경 및 동시성 문제
Couchbase는 높은 성능을 위해 메타데이터(Key + @)를 모두 메모리에 적재하는 특징이 있어서, Document 하나가 평균 350Byte를 차지하고 있었습니다. 따라서 현재 상태로 1000만개의 데이터를 저장할 경우 최소 3.5G의 메모리를, 2개의 사본(Replica)를 유지할 경우 약 10.5G의 메모리를 사용하게 될 것으로 예상되었고 이는 큰 부담으로 다가왔습니다.
처음에는 단순히 “사용자ID_연재물ID” 형태의 Key를 사용하였지만, 보다 빠르게 증가할 것으로 예상되는 것은 사용자보다 연재물 이었으므로 아래와 같이 Key값을 변경하여 메모리 사용량을 크게 줄였습니다.
// U_id : S_id 조합을 사용하면 Key가 엄청 많아진다.
// 그래서 사용자당 Key를 100개로 제한하도록 한다.
Count = 100
Key = '사용자ID' + ('연재물ID' % Count)
그런데 이렇게 Key 구조를 변경하였더니, 간단한 업데이트 동작임에도 불구하고 정상적으로 수행되지 않는 경우가 빈번하게 발생하였습니다. 이유는 낙관적 동시성(Optimistic concurrency) 모델의 특징 때문이었는데, Couchbase는 명시적인 잠금 이외에도 “Check and Set(CAS)”이라는 기능을 제공하고 있었습니다.
공식 문서의 예제를 참고하여 아래와 같이 로직을 수정한 뒤로는 다행히도 동시성 문제가 아직까지 발생하지 않고 있습니다.
boolean updateUsingCas(key, value) {
for (tryCount = 0; tryCount < MAX_TRY; tryCount++) {
orgValue, cas = getValueAndCas(key)
// Update the original value.
// newValue = ...
if setValueWithCas(key, newValue, cas)
return SUCCESS
sleep(0.1) // 부하를 줄이기 위해
}
return FAIL
}
맺으며
동작하는 서비스에 새로운 기능을 추가한다는 것은 어려운 일입니다. 특히 새로운 데이터 스토리지를 필요로 하는 일이라면 더더욱 어렵다고 생각합니다. 그리고 그럴 때일수록 설계에 많은 시간을 들여야 한다는 것을 느꼈습니다. 설계 초기에는 RDBMS의 샤딩까지 고려하였지만, 요구 사항을 구체화할수록 단순 Key-Value로도 같은 문제를 해결할 수 있음을 깨달았기 때문입니다.
또한, 서비스 개발에 있어서 어려운 문제를 마주했을 때 기술적으로만 접근할 것이 아니라 고객이 정말 원하는 것이 무엇인지를 고민하여 기획적으로 해결하는 능력도 중요하다는 것을 실감하였습니다.
마지막으로 Couchbase는 현재로서도 꽤 좋고 앞으로도 많은 발전이 기대되는 NoSQL입니다. 도입을 고민하시던 분들께 조금이라도 도움이 되었기를 바랍니다.
참고자료
[2] Couchbase – Views Operations
리디 기술 블로그
고객과 발맞춰 새로운 콘텐츠 경험을 선보이는
리디와 함께할 당신을 기다립니다.